Félreértések a statisztikai szűrők kapcsán
Nemes Dániel egy érdekes előadást tartott a tavalyi Hacktivity-n “A SPAM-ektől az összetett fenyegetésekig – technológia támadástól védekezésig” címmel. (Az előadás videoja a Hacktivity 2007 oldaláról letölthető)
A védekezés lehetőségeinél szóba került a bayes-i (=statisztikai) elv, amelynek kapcsán pár dolgot helyre szeretnék tenni. Ki tudja? Talán az idei Hacktivity 2008-on lehetőségem lesz rá.
Az előadó az alábbi problémákat látja a Bayes elv használatában (nem szó szerint idézve):
1. Meg kell húzni egy határértéket [hogy mettől tekintjük spamnek a levelet], de hol húzzuk meg? Nehéz pontosan meghatározni. Ha túl magasan húzom meg, akkor kevés spamet ismer fel, ha pedig túl alacsonyan húzom meg a határt, akkor a jó levelekre is harap a szűrő.
A legtöbb statisztikai algoritmust használó spamszűrőben egy jól eltalált alapértelmezett érték van,
a clapf-nál ez 92% (0.92). Ha a felhasználó módosítani akarja, szíve joga, azonban a legtöbb esetben a 92% megfelelő. Hihetetlenül hangzik, de a határ meghúzása valójában kevéssé lényeges. Ennek az az oka, hogy (megfelelő tanítás után) a jó levelek spam valószínűsége 0.00xx (0-1%) körül, míg a spam levelek valószínűsége a 0.99xx (99-100%) körül szóródik. A bogofilter-ben található finomhangoló program pl. akár 55%-nál is képes meghúzni a spam határt (más paraméterek egyidejű módosítása mellett).
Hogy mégis van némi szerepe a a spam határ megválasztásának, az azért van, mert (különösen a magyar levelezők életében) vannak olyan jó levelek, amelyek úgy néznek ki, mint egy spam, és olyan spamek is vannak, amelyek úgy néznek ki, mint a jó levelek. Ha mindezt grafikonon ábrázoljuk, akkor egy kettős haranggörbét kapunk. Jól látható, hogy van egy bizonytalan zóna (unsure felirattal), amelybe mind jó levelek, mind pedig spamek is esnek. Ez abban az esetben fordulhat elő, ha a levél teljesen ismeretlen, vagy ha közel hasonló számú jó ill. spam levélre jellemző tokent tartalmaz.
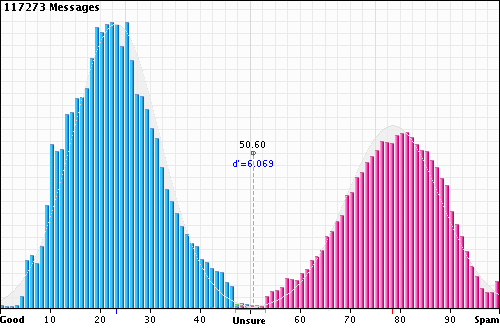
A Death2Spam projekt kategorizálta ~117k levél spam valószínűségének eloszlása.
Forrás: http://www.death2spam.com/d2s2/images/UserProbsDistrib.gif
Egy másik grafikon az inverz khi-négyzet nevű statisztikai összegző algoritmus okozta tipikus eloszlást mutatja. A vízszintes tengelyen a levelek spam valószínűsége látható, míg a függőleges tengelyen a levelek száma (logaritmikus skálán). Noha az előbb említett bizonytalan zóna itt is megfigyelhető, azonban ez – ha lehet fokozni – még drámaibb módon választja szét a jó és a spam leveleket. A jó levelek zömének a spam valószínűsége 3% alatt van, míg a spam levelek valószínűsége 98% felett van.

A SpamBayes projekt egyik felhasználójának ilyen eloszlást mutattak a leveleinek valószínűségei inverz khi-négyzet összegző algoritmust használva.
Forrás: http://spambayes.sourceforge.net/images/chi2_graph.png
2. Honnan származik az adatbázis minta, amivel tanítom? Ha az enyém, akkor nem reprezentatív. Ha egy szervezet gyűjti össze, akkor az én email forgalmam szempontjából irreleváns.
A statisztikai szűrők pontossága a tanítással arányos. Ezért nagyon fontos, hogy a felhasználó saját levelei megfelelően reprezentálva legyenek a statisztikai spamszűrő adatbázisában, ellenkező esetben hibákat fog véteni a program. A jó levelekre jellemző, hogy ahány felhasználó, annyiféle jó leveleik vannak, továbbá a jó leveleik általában lassan változnak. A spameket viszont ezzel ellentétben nagy tömegben küldik ki, lényegében azonos tartalommal, és a spam gyorsan változik (bár a havi pár ezer spam leveleimben jó, ha 10-féle spam váltja egymást).
Ebből az következik, hogy (elvben) az a legjobb, ha a ham adatbázisunkat a saját leveleink alapján állítjuk össze, míg a spam adatbázist egy nagy, profi és speciálisan ezzel foglalkozó cégtől szerezzük be, akik rengeteg spammel találkoznak, így nagyon reprezentált és aktuális mintával rendelkeznek.
A gyakorlatban ez azonban nem működik, mert aligha van olyan anti-spam gyártó cég, aki a drága áron (értsd: költsége van) összeszedett adatbázisát ingyen (vagy akár térítés ellenében) szétosztaná. De nem is van erre feltétlen szükségünk, mert pl. vállalati környezetben bőven elég lehet 1-2 hónapnyi összegyűjtött spam levél, ill. egy csapda email cím segítségével a spammereket is megkérhetjük, hogy segítsenek frissen tartani a spam leveleinket (anélkül, hogy a felhasználóinknak találkozniuk kellene az ilyen spamekkel). Hihetetlen, de a spammerek meg is teszik ezt a szívességet (persze, nem önszántukból, de ez most mindegy).
3. Folyamatos menedzsmentet igényel. Ki végzi el? A rendszergazda vagy egy 3. fél?
Nem igényel. A saját gépemen futtatott clapf-ot persze folyamatosan szemmel tartom, de ez azért egyedi jelenség, mert a programot én fejlesztem, és – mint fejlesztő – új funkciókat tesztelek, csiszolgatom, stb. A felhasználók szempontjából a clapf egy láthatatlan köztes alkalmazás, amely úgy működik, mint az ember veséje, azaz rendesen nem is tudjuk, hogy van olyanunk is.
Ha pedig “folyamatos menedzsment” alatt a folyamatos tanítástól félünk, akkor hadd nyugtassak meg mindenkit: ha van egy erős kezdeti tanítás (amit tipikusan a vállalat rendszergazdája végezhet el – amit elég egyszer megtenni), akkor aligha kell a felhasználóknak folyamatosan tanítani a token adatbázist.
4. Bayes mérgezés.
Ez akár még működhet is, de a) ez időt és befektetést igényel a spammertől, márpedig ők minél hamarabb túl akarnak esni a levélszemét kiküldésén, b) a felhasználónak automatikus tanításra kell beállítani a spamszűrőjét, és c) a spamszűrőnek fel kell használnia a nem standard levél fejléceket is. Ez implementáció függő, vannak olyan spamszűrők, amelyek csak bizonyos fejléc elemekkel foglalkoznak (pl. Subject, From, To, Received és esetleg a Message-ID), a többit pedig figyelmen kívül hagyják. Ebben az esetben aligha fog működni a trükk. Ha pedig mégis átcsúszik végül a spam levél, akkor egyetlen tanítás semlegesítheti a spammer trójai tokenjeit, és kezdheti a spammer az egész cécót elölről.
5. Töltelékszavak a levél elején, végén, közepén, hogy ezek lerontsák a felismerés hatékonyságát. Spamre nem jellemző szavakat tesznek bele, így fog átjutni a spamszűrőn. Ha tanítod, akkor mérgezi az adatbázist, sokkal rosszabbul fog működni.
J.G. Cumming végzett egy tesztet, amelyben egy spamként felismert piko spamet módosított úgy, hogy a Wikipedia-ról, a szótárfájlból véletlenszerűen ollózott be töltelékszavakat. Az eredmény: a piko spam tízezerszámra küldött mutációiból mindössze 0.04% jutott át. Elhanyagolható.
6. A nem szöveges, pl. kép alapú spamekkel mit kezdenek ezek a programok?
A csak képes mellékletet tartalmazó spam is tartalmaz használható szöveges részt (nem az ilyen levelek végén található kötelező (sic!) szósalátára gondolok), pl. a szükséges HTML részlet, domain nevek, SMTP útvonal (a “Received” fejlécekből), stb. Emellett – ha a spamszűrő bizonytalan – a feladó IP-címét össze lehet vetni feketelistákkal, vagy kimondhatjuk azt is, hogy ha valaki képet küld, és a levele nem jó levél (azaz a spam valószínűsége egy bizonyos határ alatt van), akkor azt spamnek tekintjük. Ezt az utóbbi elvet használva, jó ha 2 fals pozitívom volt az utóbbi hónapokban, cserébe viszont meg tudtam fogni egy nagy halom képes spamet.
7. A Bayes alapú technológiák megbízhatósága kétséges, kétségbe vonható.
Megcáfolva. A bizonyítást ld. fentebb, ill. a SPAMtelenül című könyvemben, amely az áprilisi könyvfesztiválon mutatkozik be. Ja, és hogy miért hoztam elő a témát? Mert Nemes Dániel megemlítette az inverz “csí” – vagy helyesebben: khi (a görög ABC betűje után szabadon) – algoritmust, és a clapf terméknév is elhangzott (mint ami az előbbi nehéz nevű algoritmust használja), amit innen is szeretnék megköszönni. Hátha idén azt is megtudhatja a Hacktivity közönsége, hogy mi az a clapf, és hogyan képes állni a sarat a spammerek trükkjeivel szemben….
Leave a Reply